
Product
Orb Is Being Acquired by Adyen. Here's What That Means If You're Evaluating Usage-Based Billing Platforms.
Anh-Tho Chuong • 8 min read
May 23, 2025
/11 min read
Usage-based pricing is now the default for AI and infrastructure companies, and it's spreading fast to the application layer. But "usage-based pricing" covers a wide range of models with very different economics. Pay-per-use is not the same as credit-based. Percentage-of-revenue is not the same as outcome-based. Hybrid is not the same as any of them.
This article walks through 10 real examples — with actual pricing where available, so you can see how each model works in practice and what it means for your own pricing decisions.
Usage-based pricing charges customers for usage within a billing cycle. The charge is tied to a measurable metric: API calls, tokens, rows, messages, seats consumed. Cost scales with value delivered. Customers who use more, pay more. Customers who use less, pay less.
SaaS companies using usage-based pricing typically bill customers using measurable value metrics. The company tracks usage over a billing period, applies the unit price, and bills accordingly.
Usage-based pricing is most common in infrastructure (cloud services, databases, DevTools, APIs.) because costs per customer are more varied: A database customer with 100 users costs much less than one with millions of users. It wouldn't be fair to charge them the same.
With AI, usage-based pricing has arrived at the application layer. Apps are more likely to charge a subscription that includes usage (via credits or other forms of hybrid pricing) to keep it simple for users.
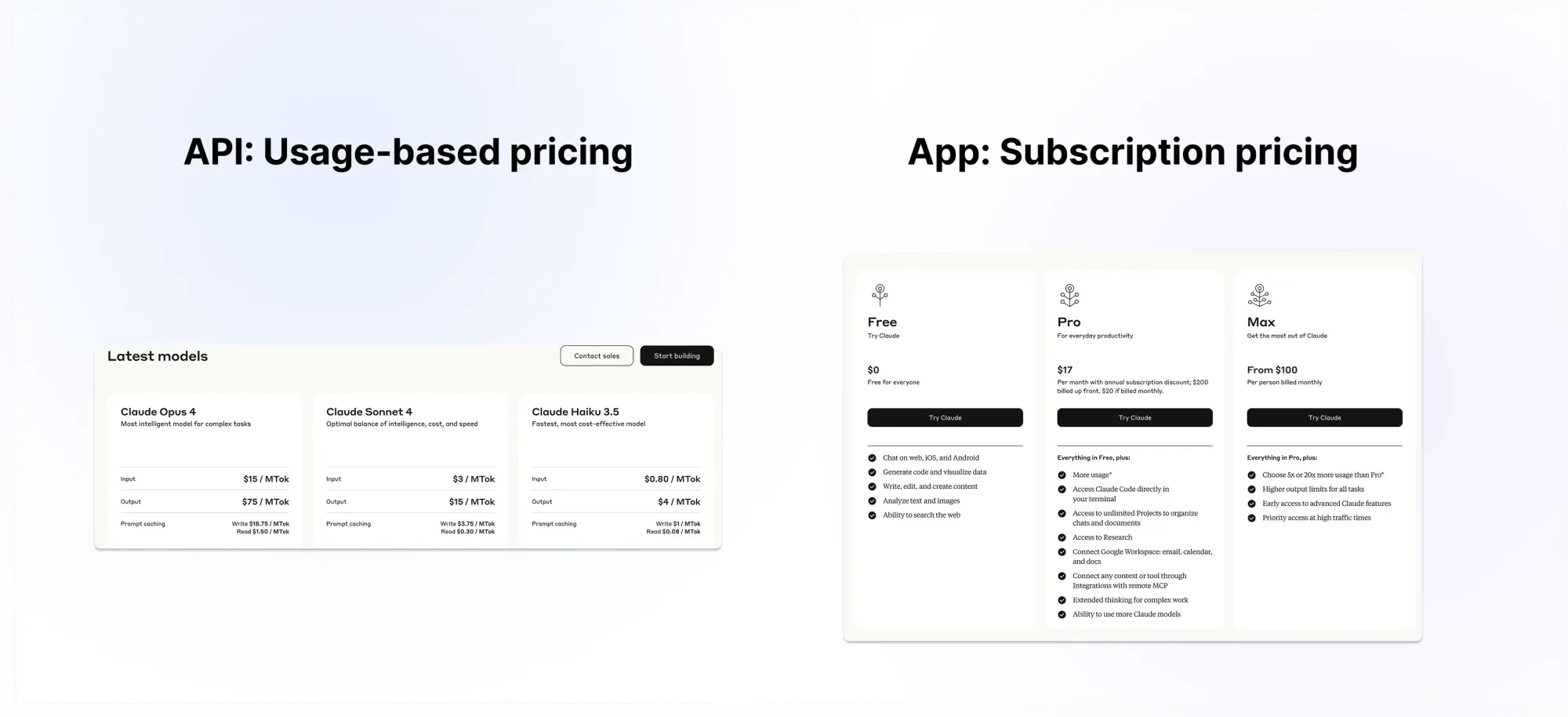
Usage-based pricing is unlikely to work in scenarios where users don't get value out of each bit of usage. For example, nobody would like to pay for Figma by the frame. A great example of this contrast is Anthropic's Claude, where the API is priced on usage while the app is paid for by subscription. The underlying AI is the same.
One frame that helps: usage-based pricing works when your marginal cost per customer varies significantly. If your heaviest user costs you 100x more to serve than your lightest user, flat subscription pricing mixes margins in a way that's hard to sustain. If costs are relatively fixed per customer, a subscription is simpler and more predictable.
No flat fee. No minimum. Pay exactly for what you consume.

AWS S3 pricing in 2026: $0.023 per GB stored per month for the first 50TB, $0.022 for the next 450TB, $0.021 beyond that. Data transfer out: $0.09/GB for the first 10TB. Each service — EC2, Lambda, RDS, CloudFront — has its own consumption metric and rate schedule. A small startup running lightweight workloads might pay $12/month. A company processing petabytes pays millions.
AWS is the canonical example because it proved the model at scale. The pricing page is effectively a menu — customers compose their own cost structure from dozens of individual services. The advantage is precision. The disadvantage is opacity: customers frequently can't predict their bills, which is why AWS cost management is a $3B+ third-party industry.
The trade-off pure pay-per-use always runs into: customers dislike unpredictable bills. AWS responded by building a cost explorer, alerts, budgets, and savings plans. If you go pure consumption, you need to invest in the same — or your support queue fills with billing surprises.
Twilio charges per SMS, per voice minute, per email sent, per phone number provisioned. SMS in the US: $0.0079 per message sent, $0.0079 per message received. Voice: $0.014/min to receive, $0.022/min to make. No seats. No base fee. Pure event-based billing.
What makes Twilio's model instructive: the unit of charge is the unit of value. Every SMS sent is a direct action the customer chose to take and presumably benefited from. There's no ambiguity between usage and value. That clarity is why Twilio's pricing has been copied across the entire communications API category.
The Twilio pattern also shows how volume discounts layer onto pure consumption pricing. Once a customer reaches certain monthly volumes, per-message rates drop automatically. This rewards growth without requiring sales negotiation — the pricing table does the upsell.
Snowflake separates compute from storage — a design decision that's become a template for data infrastructure pricing. Storage: $23/TB/month for on-demand. Compute: priced in "credits," where one credit costs $2–$4 depending on cloud and region. A small warehouse consumes 1 credit/hour; a 4XL warehouse consumes 128 credits/hour.
This model is sophisticated for two reasons. First, separating compute and storage means customers only pay for processing when they're running queries — idle data doesn't burn compute credits. Second, the credit abstraction lets Snowflake change underlying infrastructure costs without repricing the customer-facing rate.
The downside is well-documented: query costs can spike unpredictably during experimentation or seasonal data loads. Snowflake's answer was query budgets and resource monitors. The lesson: the more variable your consumption metric, the more spending controls you need to ship alongside the pricing model.
Credit-based pricing is perhaps the most popular AI pricing model for generative AI apps. It means issuing a number of credits to users which are included in their subscription. These credits can be spent on using the product. When users run out of credits, they can either top up their wallets by buying more or wait until credits are replenished at the next billing cycle.
Credits work best when users directly initiate usage. The credit model solves a specific problem: AI inference costs are variable and hard for customers to reason about. Rather than exposing raw token prices, Relevance AI abstracts usage into credits — a layer of indirection that makes pricing feel predictable even when underlying costs are not.
Relevance AI's 2026 pricing: Free (100 credits/day), Starter ($19/month, 1,500 credits/month), Team ($199/month, 15,000 credits/month), Business ($599/month, plus custom volume). Credits are consumed by agent runs, with cost varying by task complexity.
The credit model's real risk is credit-to-value opacity. If customers can't easily calculate how many credits a given action will consume, they lose trust in the pricing. Relevance AI addresses this with a credit calculator on the pricing page. That's the right move — if you use credits, you need to make the conversion obvious.
An example of this is AI agent platform Relevance AI:

Mistral charges per million tokens: input and output are priced separately, with rates varying by model. Mistral Large 2: $2/million input tokens, $6/million output tokens. Mistral Small: $0.10/$0.30. Codestral (code generation): $0.10/$0.30.
Mistral is a Lago customer — the token metering that drives their billing runs through Lago's event ingestion and rating engine. The token-based model works for them for a clear reason: inference cost scales directly with token count. Input and output pricing separately reflects the actual compute asymmetry — generating tokens is more expensive than processing them.
The Mistral model is also instructive for how AI companies handle enterprise: volume commitments with pre-purchased token packs, which give Mistral upfront cash and give enterprise customers rate certainty. The listed per-token price is the default; the enterprise rate is negotiated off a commitment floor. That's the standard AI API commercial structure in 2026.
Some companies charge a percentage of another metric, typically revenue. Stripe charges a fixed percentage of each transaction: 2.9% + $0.30 per successful card charge in the US.
Stripe's percentage model has an elegant property: Stripe only makes meaningful revenue when its customers make meaningful revenue. That alignment is why payment processors have always used this model — and why it's hard to replicate outside of payments, where the transaction value is inherently visible to the vendor.

The model also has a natural ceiling problem at scale. A company processing $1B/year pays Stripe ~$29M — at which point the build-vs-buy calculus on payments infrastructure becomes very different. Stripe's answer has been enterprise negotiation and Stripe Treasury to expand the relationship beyond per-transaction fees.
Outcome-based pricing only charges for success. Two current examples:
Chargeflow: ~25% of recovered chargebacks (or $39 per prevented chargeback). You only pay when Chargeflow wins. Zero cost if it fails.
Intercom Fin: charges per AI-resolved support ticket. If Fin doesn't resolve the conversation, you don't pay. In 2026, outcome-based pricing is the dominant commercial model for AI agents — Salesforce Agentforce is per-conversation, Intercom Fin is per-resolution, Klarna's AI customer service is structured the same way.

The attribution problem is real and gets worse at scale. What counts as "resolved"? What if the customer reopens the ticket? What if the AI partially resolved it but a human had to finish? These edge cases require clear contract language and billing systems that can handle conditional invoicing. Most billing infrastructure wasn't designed for this — it's why outcome-based pricing is growing but still operationally hard.
The reason it's spreading despite the complexity: from a sales perspective, it's the easiest pricing to close. Customers don't need to model ROI — the ROI is the pricing mechanism itself.
Hybrid pricing combines aspects of usage-based pricing with a subscription model. A great example of this is Supabase. The database company charges a subscription which includes usage and then charges a pay-per-use fee on top of it for additional storage or active users.

Supabase's 2026 pricing: Free tier (500MB DB, 1GB file storage, 5GB bandwidth), Pro tier ($25/month including 8GB DB, 100GB storage, 250GB bandwidth), then overages at specific per-unit rates beyond the included allocation. The database never stops — customers can't run out of credits. But usage beyond plan limits generates additional charges.
But hybrid billing models also exist outside of infrastructure. Take email and SMS marketing vendor Brevo as an example:

This is the model most AI-era SaaS companies converge on: subscription for the floor, consumption for the ceiling. The subscription creates ARR predictability. The usage component captures expansion revenue when customers grow without requiring a seat upgrade negotiation.
Brevo (email and SMS marketing) charges a subscription for features and then prices email sends by volume tier above the plan's included allocation. Free: 300 emails/day. Starter: from $9/month for 5,000 emails/month. Business: from $18/month for 5,000 emails/month with automation features unlocked.
What's notable about Brevo's model: the subscription gates features (automation, A/B testing, landing pages), while the usage meter gates volume. The two dimensions are independent. A customer can be on the lowest subscription tier but send high volume — they pay per-send overages. Or they can be on the highest tier and send low volume — they pay for features they're only partially using.
This decoupling of feature access from usage volume is increasingly common and harder to price correctly. It requires billing infrastructure that can simultaneously track feature entitlements and usage events as separate, parallel billing tracks.
Blacksmith provides GitHub Actions runners and charges by the minute of compute used — faster runners, more cost per minute. Their pricing is structured around runner type (standard 2x, 4x, 8x faster than GitHub-hosted) and compute minutes consumed.
Blacksmith runs on Lago. They built usage-based billing for CI/CD infrastructure — a category where seat pricing makes no sense (two engineers can generate radically different CI load) and where the value delivered is directly proportional to time saved on builds. In their first year, they onboarded 700+ customers on this model.
The Blacksmith case is instructive for developer tools: consumption-based pricing removes the enterprise procurement conversation entirely. Customers connect their GitHub org, start running jobs, pay for what they use. No sales negotiation needed until they want volume discounts or custom SLAs.
Implementing usage-based pricing has three steps that have to work in sequence: pick the right charge metric, instrument it reliably, and give customers visibility into what they're accumulating.
The charge metric is the most important decision. It needs to track value closely enough that customers accept it as fair, and it needs to map to your infrastructure costs closely enough that your margins stay intact. Tokens are good for AI inference because they proxy both. Minutes are good for CI/CD because time directly correlates with compute consumed. Seats are bad for AI because two seats can represent wildly different infrastructure loads.
Reliable metering means capturing every event at the point of consumption, deduplicating retries, handling late-arriving events, and making the raw data auditable. Companies on usage-based models lose 2–5% of ARR to metering gaps — Lago tracks this across its customer base. That's not a billing system problem so much as an instrumentation problem. Fix the gaps at the source.
Usage visibility is not optional. Every example above — AWS, Snowflake, Twilio, Supabase, Brevo — ships a real-time usage dashboard. Customers who can see their usage don't call support. Customers who can't will churn when the bill arrives.
Lago is open-source billing infrastructure that handles metering, rating, invoicing, and credits for usage-based and hybrid models. Mistral and Blacksmith both run on it.
Where usage-based pricing is heading
The 61% of SaaS companies looking to launch consumption-based models are mostly moving toward hybrid, not pure pay-per-use. Pure pay-per-use is hard to forecast for both sides. Hybrid — subscription floor plus usage ceiling — is where the market is settling.
The next evolution is outcome-based pricing, driven by AI agents. When software acts autonomously on behalf of customers, customers want to pay for results, not for compute. Salesforce Agentforce per-conversation, Intercom Fin per-resolution, Klarna's AI customer service — all outcome-based. Billing systems that can't handle conditional invoicing (charge only if the outcome occurred) will be a bottleneck for this model.
The companies that figure out how to instrument outcomes reliably will have a structural pricing advantage. It's the hardest model to operationalize and the easiest to sell. That combination usually signals where a market is going.
UBP charges customers for actual consumption—whether API calls, data rows, or credits—instead of a flat monthly seat fee.
Seat‑based ties cost to users; flat‑rate is one price for unlimited use. UBP scales costs (and value) with measurable activity, aligning spend with usage.
Common value metrics include tokens processed, inference seconds, images generated, or characters translated—anything closely tied to cloud‑compute costs.
Use a hybrid when you need predictable recurring revenue and want to let power users burst beyond included usage without upgrading tiers.
Offer real‑time usage dashboards, spend alerts, and hard limits or auto‑top‑ups so buyers stay in control.
It can add volatility, but cohort analysis, usage caps, and minimum‑commit contracts improve predictability while preserving upside.
You'll need metering, rating, and invoicing that handle high‑volume events in near‑real time—tools like Lago, Stripe Billing, or custom Kafka pipelines.
Choose a metric customers understand, map it to delivered value, and ensure you can measure it accurately and cheaply.
Rarely. If users don't perceive incremental value per action (e.g., drawing a Figma frame), UBP feels punitive; subscription tiers work better.
When priced fairly, churn often drops because users aren't forced to over‑subscribe; they can scale down during quiet periods without canceling outright.
Best‑in‑class usage‑based companies report 120 %–140 % NDR, driven by organic expansion as customer usage grows.
Communicate early, grandfather legacy plans, and offer usage credits or discounts during the transition to build goodwill.


